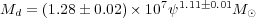
Fitting a self-consistent model over the divide between stellar and dust emission in the SED is of course one of the ultimate goals of SED fitting. However, while modelling efforts are well-underway (see Section 2.2.3), unfortunately, few authors have attempted to apply these to large samples of galaxies. Inversion techniques are not applicable here, as the problem is highly non-linear with many free parameters and therefore time consuming. Even for calculation of a library of model galaxies, it is challenging to provide models that are sufficiently simple, complete and fast to make this a practical possibility.
We here need to bypass instances where modellers test their codes on single galaxies (e.g. Silva et al. 1998; Popescu et al. 2000; Groves et al. 2008). This is of course a most valuable and necessary step to make sure that the model does bear on our understanding of reality and to further our knowledge of the underlying physics. Most of the results from these studies have been presented above in Section 2. For the potential novice reader of this manuscript we nevertheless emphasize at this point that proper filter convolution and χ2 fitting cannot be replaced by by-eye passing of spectra through photometric data points.
Using the model by da Cunha, Charlot, and Elbaz (2008), in a follow-up paper da Cunha et al. (2010) have demonstrated the strength of fitting the full SED from UV to IR wavelengths. By fitting the full SEDs of ~ 3000 galaxies with GALEX, SDSS, 2MASS, and IRAS data, they were able to determine the star formation rate, the star formation history as measured by the specific star formation (ψs =current 0 - 108Myr star formation rate divided by the past average star formation rate), dust and stellar masses and other parameters. They found a strong correlation of dust mass (Md) to star formation rate (ψ, in M⊙ yr-1 ), shown below in equation 6), as well as relations between the dust to stellar mass ratio and ψs, and the fraction of IR emission arising from the diffuse ISM and ψs .
|
| (6) |
This work demonstrates clearly the connection between dust mass, star formation history and stellar evolution.
Iglesias-Páramo et al. (2007) have gone to the length of using the GRASIL code (Silva et al. 1998) to compute a library of 5000 model galaxies and then use Bayesian inference to derive the properties of their sample. Their general results agreed well with independent studies by other authors, thus lending support to the notion that full SED fitting is a reliable tool to derive galaxy properties. More importantly in the present context, they show that their reduced χ2 distribution has a median value of 2.6, albeit with a long tail extending well above 10. Thus the GRASIL library is found to reproduce their sample fairly well. Nevertheless, from the point of view of reliable SED fitting tools, a more thorough analysis of the outliers (model uncertainties, incomplete libraries, AGN, etc.) would be valuable, not only in this but in many other works.
Noll et al. (2009) present a new code, which they call ”CIGALE”, which effectively computes a library of model galaxies and then uses a modified version of the Bayesian inference described in Section 4.5 to determine the galaxy properties. Diagnostic plots like their Figure 14, which shows the residuals between best fit model and data for their full sample, are a very useful tool to understand model systematics. In their case for example, they conclude that ”For MIPS 160 μm the significant deviations can partly be explained by the lacking flexibility of the one-parameter models of Dale and Helou (2002).”
As shown by the last two examples, most UV-FIR SED fitting codes are still in their testing phase and have mostly been used to confirm results already obtained from more traditional single-tracer analyses. The large number of derived parameters and our still limited knowledge of their respective degeneracies and systematic uncertainties make it difficult to go a step further and fully use the full power of SED fitting. Indeed, for the moment it is still questionable whether it is not more fruitful to use a combination of single tracers to derive one property well (e.g. Kennicutt et al. 2009, for SFR). On the long run, however, SED fitting holds the promise to provide a large set of galaxy properties for large samples. Self-consistent inter-comparison of sub-samples with different properties, such as masses and SFRs, and the exploitation of constraints on hitherto unconstrainable parameters, such as the relative weights of young, intermediate age and old populations, are an exciting avenue to explore further in the future.